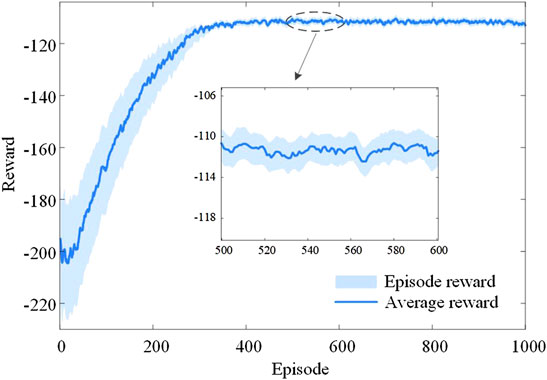
The cumulative number of learning steps. Our modified DDPG
$ 8.99 · 4.9 (71) · In stock

Frontiers A Modified Long Short-Term Memory-Deep Deterministic
Meta-Policy Gradients: A Survey - Rob's Homepage

In this figure, we compare Gaussian process regression (GPR) in a

Mohammad Ali ZAMANI, Researcher, PhD fellow, R&D

Simulated environment with train and test targets. Blue circles

Sensors, Free Full-Text

Matthias KERZEL, Research Assistant, PhD

Processes, Free Full-Text

The cumulative number of learning steps. Our modified DDPG

NOMA resource allocation method in IoV based on prioritized DQN

Distributed deep reinforcement learning-based multi-objective

Hadi BEIK MOHAMMADI, PhD Student

The cumulative number of learning steps. Our modified DDPG








